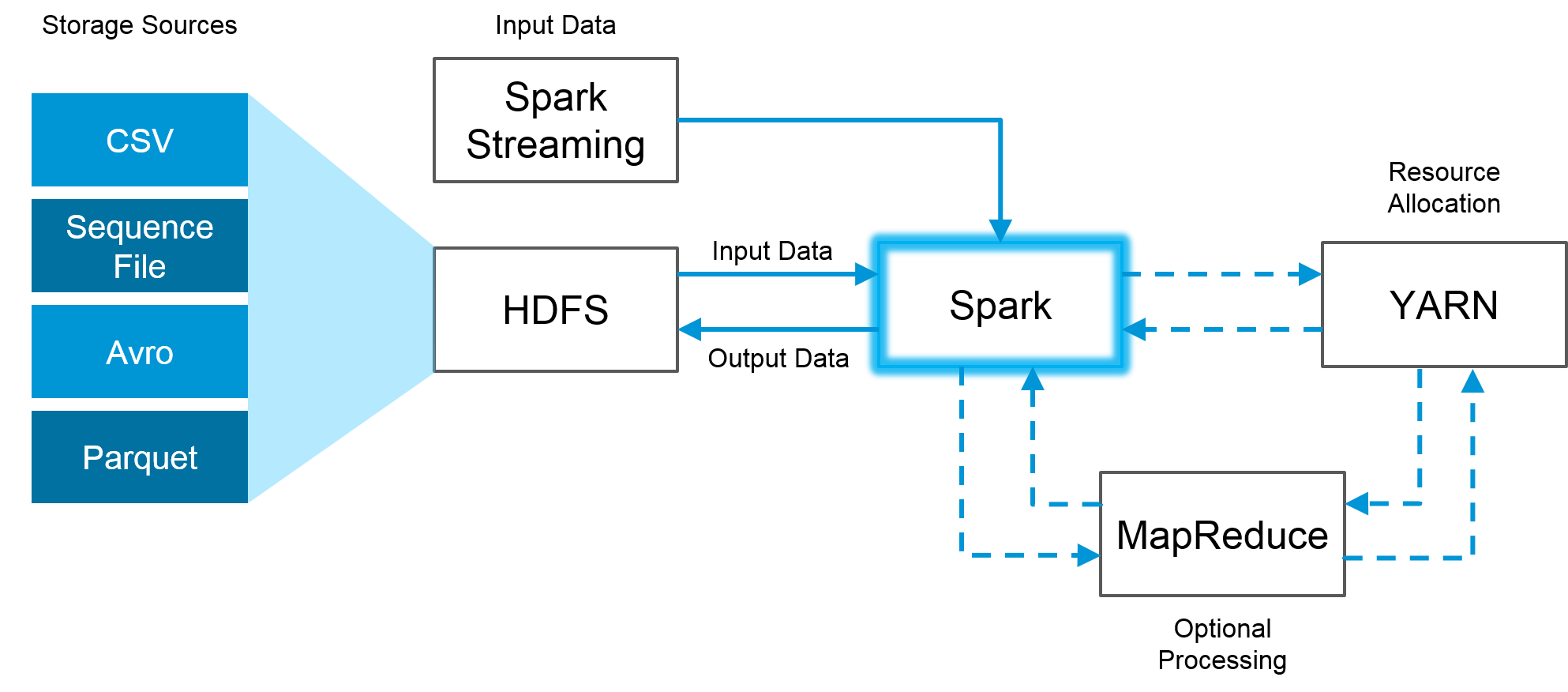
El procesamiento de grandes volúmenes de datos se ha vuelto esencial para muchas empresas, y Spark se ha convertido en una de las herramientas más populares para hacerlo. A medida que los datos se vuelven más complejos, la necesidad de optimizar el procesamiento se vuelve cada vez más importante. En este artículo, exploraremos cómo los dataframes y pipelines en Spark pueden ayudar a optimizar el procesamiento de datos.
Dataframes en Spark: Estructuras de Datos para Procesamiento
Los dataframes son una estructura de datos en Spark que se asemeja a una tabla en una base de datos relacional. Cada fila representa un registro y cada columna representa un campo de ese registro. Los dataframes en Spark se pueden construir a partir de varios tipos de datos, incluyendo CSV, JSON y parquet.
Los dataframes en Spark también tienen algunas características interesantes, como la capacidad de realizar operaciones de agregación, filtrado y ordenamiento. Los dataframes también son inmutables, lo que significa que no se pueden modificar una vez que se han creado.
Pipelines en Spark: Flujo de Procesamiento de Datos
Los pipelines en Spark son una forma de organizar y ejecutar una serie de transformaciones de datos de manera secuencial. Cada etapa en un pipeline toma un conjunto de datos como entrada, lo transforma y produce un conjunto de datos de salida que se utiliza como entrada para la siguiente etapa.
Los pipelines en Spark son muy útiles para procesar grandes volúmenes de datos de manera eficiente y escalable. Las transformaciones en un pipeline se ejecutan en paralelo, lo que significa que el procesamiento se puede distribuir en varios nodos de un clúster Spark.
Optimización de Procesamiento de Datos en Spark
La optimización del procesamiento de datos en Spark se puede lograr de varias maneras. Una de las formas más comunes es utilizar la partición de datos para distribuir la carga de trabajo en varios nodos. La partición de datos implica dividir los datos en varias particiones, cada una de las cuales se procesa en un nodo diferente.
Otra forma de optimizar el procesamiento de datos en Spark es utilizar la cache de datos. La cache de datos es una técnica que almacena datos en la memoria para un acceso más rápido. Al almacenar los datos en la memoria, se puede evitar la necesidad de leer los datos desde el disco, lo que puede ser significativamente más lento.
Uso de Dataframes y Pipelines para Análisis de Grandes Volúmenes de Datos
El uso de dataframes y pipelines en Spark es muy común para el análisis de grandes volúmenes de datos. Los dataframes se pueden utilizar para representar grandes conjuntos de datos y realizar operaciones de agregación, filtrado y ordenamiento en ellos. Los pipelines se pueden utilizar para organizar y ejecutar un flujo de trabajo de transformación de datos.
El uso de dataframes y pipelines en Spark también es muy escalable. Los pipelines pueden ejecutarse en un clúster de Spark, lo que significa que el procesamiento se puede distribuir en varios nodos. Los dataframes también se pueden particionar para distribuir la carga de trabajo en varios nodos. Esto hace que el procesamiento de grandes volúmenes de datos sea más rápido y eficiente.
En conclusión, los dataframes y pipelines en Spark son herramientas esenciales para el procesamiento y análisis de grandes volúmenes de datos. Al utilizar técnicas de optimización como la partición de datos y la cache, se puede mejorar significativamente el rendimiento del procesamiento. Si está trabajando con datos grandes y complejos, el uso de dataframes y pipelines en Spark es una necesidad.